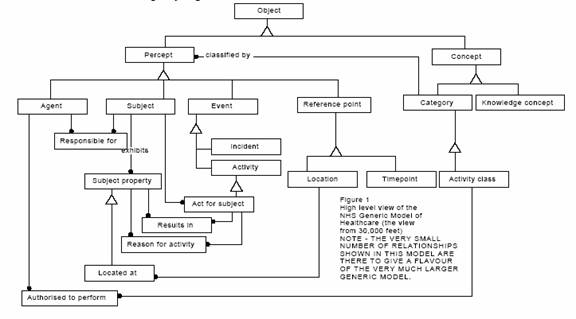
The debate about the promised value of the Semantic Web seems to me to be missing a dispassionate examination of the success, or otherwise, of existing ontology based solutions. Clay Shirky is obviously right when he states that a single monolithic ontology will never work. His critics are equally right when they claim the Semantic web will only work if it is a melange of multiple interoperable Ontologies. What is missing from the debate is a more detailed explanation of what ontologies are good at, how they interoperate, and why systems based on ontologies succeed or fail. From my perspective as a systems designer this last point is the most significant. Debates about theory are nice, but examples of real solutions are more instructive. This essay will begin to examine this question by attempting to define the anatomy of an ontology. I will use this structure in later essays to examine the reasons for success and failure of individual ontologies.
Ontologies are nice, in theory, but difficult to extract value from, in practice. They fail for a variety of reasons: The fundamental assumptions on which they are based are often unsound. Sometimes they are inflexible and unable to adapt to new circumstances. Or, conversely, while attempting to make them adaptable their designers make them too abstract for the people who are then burdened with their implementation. Frequently they are inadequately specified, leaving vital areas open to interpretation, thus negating their usefulness. And just as frequently they are designed without consideration for interoperability with other ontologies – ironic considering their basic purpose. Despite all these opportunities for failure successful ontologies can be spectacularly powerful.
To analyze the success or failure of example ontologies it will be necessary to first define the anatomy or architecture of an ontology. By defining the roles and responsibilities of the component parts of an ontology it will be possible to explain the success or failure of various examples in terms of these components. Ontologies can vary widely in complexity. Some contain all the components listed below but many do not. The anatomy I develop below is based on practical experience of what has worked in systems I have designed, reviewed, or studied. This anatomy may not; be consistent with text books, agree with the latest theory, or reflect current best practice. It does however work for me. It may work for you, but I make no promises.
Ontologies in Theory
Tom Gruber of Stanford University defines the word Ontology as :-
A specification of a conceptualization. That is, an ontology is a description (like a formal specification of a program) of the concepts and relationships that can exist for an agent or a community of agents.
An Ontology can be thought of as a contract shared between agents that intend to exchange information. The contract takes the form of a model for structuring and interpreting exchanged data and a vocabulary that constrains these exchanges. Using a relatively small ontology agents can exchange vast quantities of data and consistently interpret it to extract information. Furthermore they can, in principle, infer new information by applying logical rules allowed, and sometimes explicitly specified, by the Ontology.
It is worth remembering that every non-trivial ontology will allow logical inconsistencies. As Godel pointed out in his Incompleteness Theorem – In any axiomatic system it is possible to create propositions that cannot be proved or disproved. This does not negate the usefulness of ontologies just as it does not negate the usefulness of mathematics. However it does mean ontologies, like everything else, have their limitations.
The sense of the word “Ontology” defined above was defined by the Artificial Intelligence research community after they stole the word from the field of philosophy. More recently it has been adopted to describe components of the Semantic Web. In the AI community the ability to infer new information from existing data is of fundamental importance and this is sometimes misinterpreted as a defining feature of an ontology. In fact many ontologies support this capability only weakly, if at all. The word is also sometimes narrowly defined to mean hierarchical taxonomies or constrained vocabularies, this usage is too narrow since an ontology also contains assertions about how data can be structured and interpreted and these assertions are missing from taxonomies and constrained vocabularies.
The following brief summary taken from the essay What are the differences between a vocabulary, a taxonomy, a thesaurus, an ontology, and a meta-model? by Johannes Ernst provides a good description of the various frameworks often classified as ontologies.
Taxonomies and Thesauri may relate terms in a controlled vocabulary via parent-child and associative relationships, but do not contain explicit grammar rules to constrain how to use controlled vocabulary terms to express (model) something meaningful within a domain of interest. A meta-model is an ontology used by modelers. People make commitments to use a specific controlled vocabulary or ontology for a domain of interest
For the purpose of this essay I will use a broad definition for the word ontology
Ontology :- A specification of a conceptualization used by a community of agents to support the exchange and consistent use of information.
Ontologies in Practice
Ontologies, far from being an unproven new concept, are already in practical daily use. They form the foundation of classification systems, databases, and object oriented software applications. In a few notable cases ontologies have persisted and even evolved over many decades. What is new is the realization that all these seemingly different systems can be compared from an ontological point of view. With the rise of the Internet and the more recent global adoption of the Web the desire to discover and exchange information, rather than mere data, has grown. Developing methods to allow the interoperation of existing and new ontologies has become imperative – hence the efforts being expended on the development of the Semantic Web.
Ontologies in Context
The value of an ontology can only be judged by its ability to support the exchange of information between agents. An ontology considered outside its context of use is a meaningless abstraction. It is only when a number of agents agree to use the same ontology to constrain their interactions that it gains any value. Most ontologies, especially successful ones, are less than perfect. Every useful ontology is a compromise between the conflicting needs of different agents. To fully appreciate the ability of an ontology to successfully support the exchange of information it is necessary to examine the instance data that is exchanged. All too often ontologies are presented in isolation as if they were the end of the story when in fact they are only the beginning of the dialog. The exchange is what is important not the ontology. For this reason I also include the instance data in the discussion below even though it is strictly not part of an ontology. It is worth noting that use cases are an essential part of ontology design. An ontology provided without supporting use cases is likely to be a failure.
General Purpose and Single Purpose Ontologies
There are two basic types of ontology :- General purpose and single purpose. A General purpose ontology is analogous to a Universal Turing Machine in that it is capable of defining any other arbitrary ontology just as a Universal Turing Machine is capable of defining any other arbitrary Turing machine. General purpose ontologies are also capable of defining themselves. Self-definition is an significant capability because it provides for auto-discovery by both programmers and programs.
For example, a program or programmer that can read and understand xml schema is theoretically capable of examining the definition of the xml language (itself written in xml) and auto-discovering new features should they be introduced at some point in the future. Thus programmers and programs need only be taught one ontology definition language if that language is auto-defining. Codd understood this need for self-definition when he specified rule 4 of his 12 rules.
Codds Rule 4 – Active online catalog based on the relational model
The system is required to support an online, inline, relational catalog that is accessible to authorized users by means of their regular query language.
And if you don’t believe relational databases are ontologies you should read this.
Self-definition is only one of the benefits of general purpose ontologies. The other is the ability to define new arbitrarily complex ontologies. Paul Rendell has used John Conway’s game of life (a set of rules defining a simple tile game) to implement a Turing machine. This mind boggling example proves that the game of life is Turing complete and neatly illustrates how massive complexity can arise from a very simple specification. Another similar example is the XSLT Turing machine. In this example XSLT itself defined in XML is used to define a Turing Machine.
Self definition and the ability to define arbitrarily complex ontologies is more than a party-trick. Consider the C programming language. The first C compiler was written in a programming language called B by Dennis Ritchie. The first thing he wrote in C was another C compiler which he compiled using the compiler written in B. He then created another executable compiler from the same C source code this time using the new pure C compiler. Since he now had the source code for a C compiler written in C and an executable version of that same code he was free of the B language forever.
General purpose ontologies capable of self definition have existed for a century at the most and have only had any practical application outside mathematics and philosophy since the widespread adoption of the computer in the 1960′s and 70′s. Special purpose ontologies are a different matter. There are many successful special purpose ontologies that are not defined by any formal language (yet) but are never-the-less formally defined. I will examine several of these in later entries but for the time being two examples will illustrate their value.
The periodic table is a classic widely used taxonomy. It becomes an ontology when it is combined with the following assertions and constants. (Please forgive me for any errors in these rules I am not a chemist.)
- A molecule is the smallest quantity of a compound composed of chemically bonded elements
- A chemical reaction occurs when reactants (elements and/or molecules) combine to produce products (elements and/or molecules) of different composition
- Mass is conserved in a chemical reaction
- Elements cannot be transmuted in a chemical reaction
- A Mole of any compound is the product of the Avogadro number and the sum of the atomic masses of its constituent elements
This classic chemistry ontology has withstood the attacks of scientist and abuse of school children for 200 years. It allows chemists to test the plausibility of any possible chemical reaction and predict the quantities of reaction products. The system is not perfect it cannot predict if reactions are thermodynamically likely, and it cannot predict some element properties, for example why Mercury is a liquid, but it can rule out many implausible chemical reactions. Most spectacularly it has been used to infer the existence of undiscovered elements and compounds.
The Benesh Movement Notation is an ontology with a very different purpose. It is a system for recording any form of human movement. Expert Choreologists can use the notation to record entire ballets with multiple, interacting performers so that other choreologist can recreate the ballet in high fidelity without the original choreographer being present. The system records human movement symbolically on a musical stave so that the movements can be synchronized with a musical accompaniment. The system is superior to video since it can record the intentions of the original choreographer rather than the individual interpretation created by a particular performer.
Special purpose ontologies are common. Some are widely used and some are very specialized, many are successful. All these ontologies will gradually be defined by general purpose ontology definition languages so they can be made to interoperate with other similar or overlapping ontologies. By studying these successful and in some cases long-lived ontologies we can learn a great deal about how to make the semantic web successful. Even interoperability of ontologies is not a new problem (more on interoperability in a later entry).
Anatomy of an Ontology. A Five Layer Model
It may be claimed that the model presented here is really a three layer model and that layers 0 and 4 are not strictly part of an ontology. This is true but it is necessary to consider all five layers when evaluating an ontology since they all affect the fitness for purpose of the complete solution.
Layer 0. Ontology Definition Language
The days of informally defined special purpose ontologies are over. From now on anyone taking the trouble to define an ontology will use a formal specification language. All the existing special purpose ontologies will gradually be re-defined using one of the available languages. The question is which one? There are legitimate reasons for having more than one language – different language bestow different qualities on the ontologies they define. It is still early days for many of these languages and today there are few, if any, experts who can make truly informed choices. A few general observations can be made.
Ontology specification languages are not a mature technology. They are still evolving. It is likely that there will be several generations of these languages just as there were several generations of programming languages. The languages in use today will be replaced by “better” languages tomorrow. We can already see this happening, SGML has largely given way to XML and XML may in turn give way to RDF or OWL at least for certain uses. A well designed ontology has the potential to retain its usefulness for a long time and so may need to be migrated from one specification language to another. Languages that are better able to support interoperability will be a safer choice since ontologies specified with them will be easier to migrate to new “better” languages.
In choosing an ontology specification language it should be remembered the relational data model and SQL have been the default choice for the past 25 years. This approach has been phenomenally successful. There is no doubt that it works and there is plenty of support for the model in terms of tools and expertise. It is no coincidence however, that new ontology specification languages are emerging just as the web has made the Internet ubiquitous. Relational databases work well on isolated servers where encapsulation of tightly coupled data and functionality are a benefit and applications interacting with the database can be strictly controlled. But smearing a relational database across multiple unreliably networked machines is to not a good idea. It can be done, but it isn’t pretty. The new languages (XML,RDF,OWL,etc) are designed to support exactly this kind of distribution. When functionality and data are distributed, loosely coupled, and independently controlled an ontology specification language will be a much better choice.
Layer 1. Data Structures
All ontologies specify data structures. Depending on the specification language selected these could be; tables containing columns, classes with slots, statements of the form: subject, predicate, object or one of several other basic formats. Whatever language is chosen a conceptual model must be developed that defines a set of data structures that is fit for the intended use. This process is the most influential factor in determining the quality of any solution subsequently designed to use the ontology. Support for flexibility, reliability, maintainability and many other qualities is either designed into the ontology or neglected at this point. Desirable qualities such as these are frequently weakened during later stages by poor development practices, but, even good development practices will not put these qualities back in if they were never there in the first place.
In a previous essay on system design reviews I defined a set of axioms for good conceptual modeling. I have reproduced them here in summary form below. They apply equally to ontology design since an otology is merely a specification of a conceptualization.
- Everything in moderation and nothing to excess
- A good system design is based on a sound conceptual model (Architecture)
- A sound conceptual model accounts for all system requirements at a reasonable level of abstraction
- A conceptual model is sufficiently generalized when it can account for all significant use cases in a concise way that reduces complexity by consolidating similar features
- A conceptual model is sufficiently specific when it is possible to demonstrate how a system design based on the model will achieve measurable targets for required system attributes
-
A good conceptual model is easy to communicate
- A conceptual model is easier to understand and communicate if it is coherent – Logical in the relationship of it’s parts – Aesthetically consistent.
- A conceptual model is easier to understand and communicate if it is analogous to a commonly experienced, tangible, real world system
3. A conceptual model is easier to understand and communicate if it is anthropomorphized – Made to mimic human behavior, characteristics and modes of interaction
Layer 2. Assertions and Constraints
Data structures only implement part of a conceptual model. An ontology also contains a set of assertions and constraints. These assertions and constraints define rules concerning the relationships between data structures and the way the data they contain can be used.
- Integrity Constraints define what it means for operational data to be well formed or well structured. These constraints define the rules controlling validity of data such as uniqueness of; objects, records, or statements, and the cardinality and optionality of allowed relationships. Simpler constraints defined the data types for individual items like dates, numbers and specially formatted strings.
- Inference Constraints define how operational data can be combined and manipulated to produce new information – inferences. In most software applications these rules are usually static and embedded in the code and not directly accessible to other applications. However one of the features of ontology specification languages designed to support Artificial Intelligence systems is their ability to explicitly specify these rules so that external systems can learn them.
Layer 3. Reference Data
Many ontologies specify reference data in the form of constrained vocabularies, taxonomies, or thesauri. These data are used as components and classifiers of the operational data that is exchanged between agents. Agents agree on the meaning of reference data beforehand and thus can interpret exchanged messages or statements without ambiguity. Implicit in this use of reference data is the assumption that changes to the reference data will be infrequent as they will likely require version changes of the entire ontology. This is a non-trivial happening. Modification to a previously agreed constrained vocabulary may require many agents to change the way they interpret and process data and should be avoided if possible. Significant effort should be expended on considering the consequence of changes to reference data. It is too easy to ignore such issues and assume someone else will deal with problem should they arise.
Layer 4. Operational Data
Operational data, sometimes also called instance data, is supported by it’s ontology but is not part of it. The purpose of the ontology is to provide structure for the operational data. As a result it is necessary to consider the operational data when evaluating an ontology. It is my experience that there are two general types of operational data.
-
Configuration Data. This data supports the required degree of flexibility in the solution by allowing certain features to be reconfigured. Systems that make a special feature of this type of flexibility are often called data driven, In a banking solution the types of bank account and the data relating to interest rates associated with each account could be considered configuration data. This is not the same as reference data. Configuration data is expected to change and must not require a version change of the ontology. In a hospital solution configuration data may describe the wards in the hospital and the bed compliment on each ward. All agents in such a system expect these things change over time and must be capably of reconfiguring the way they process data accordingly.
-
Activity Data. Management of activity data is the main reason for the existence of any ontology. Activity data includes the actual exchanges of messages and statements between agents that have agreed to use the ontology. Without activity data everything that goes before is pointless. In a banking environment activity data could describe the opening or closing of an accounts or the actual deposits and withdrawals. In a health care setting activity data could describe clinical interventions; the x-rays and blood test performed on a patient, or at a slightly higher level the inpatient stays and diagnoses.
Summary
The success or failure of any ontology should be judged primarily by it’s ability to support the exchange of operational activity data between agents. This can only be confirmed after the ontology is implemented by assessing how the system performs in the context of use. To reduce the risk of failure in the early stages of specification the various components of the ontology should be assessed individually and collectively in terms of their ability to support required use cases for operational activity data. The design of any ontology should be assessed in terms of the following components
- Ontology Definition Language
- Data Structures
- Assertions and Constraints
- Integrity Constraints
- Inference Constraints
- Reference Data
- Operational Data
- Configuration Data
- Activity Data